

Wie man bei der Suche nach Dubletten am besten vorgeht hängt davon ab um welche Art von Dubletten es sich handelt und davon was mit den gefundenen Dubletten geschehen soll:
- Intelligente Suche nach Dubletten und doppelten Adressen mit den DataQualityTools:
Soll es besonders komfortabel sein oder handelt es sich bei den zu suchenden Dubletten um Dubletten, die nur schwer zu finden sind, dann kommt man hierfür kaum um eine speziell auf diese Problemstellung ausgerichtete Software herum. Die DataQualityTools beispielsweise finden Dubletten auch dann noch wenn diese in einem gewissen Rahmen voneinander abweichen. Das ist insbesondere bei Adresslisten hilfreich, wo Schreibfehler und Abweichungen in der Schreibweise eher die Regel denn die Ausnahme sind. Weitere informationen ... - Dubletten mit dem 'distinct'-Befehl unterdrücken:
Handelt es sich um einfach zu findende doppelte Werte, wie beispielsweise doppelte Kunden- oder Artikelnummern, und sollen diese im Ergebnis einer Datenbankabfrage einfach nur unterdrückt werden, dann bietet sich hierfür das SQL-Befehl 'distinct' an. Weitere informationen ... - Dubletten mit dem 'group by'-Befehl ausblenden:
Handelt es sich um einfach zu findende doppelte Werte, wie beispielsweise doppelte Kunden- oder Artikelnummern, und sollen diese im Ergebnis einer Datenbankabfrage einfach nur ausgeblendet werden, dann bietet sich hierfür das SQL-Befehl 'group by' an. Weitere informationen ... - Mit dem 'select'-Befehl nach Dubletten suchen:
Handelt es sich um einfach zu findende doppelte Werte, wie beispielsweise doppelte Kunden- oder Artikelnummern, und sollen die gefunden Treffer direkt aus der Datenbank herausgelöscht oder anhand des Ergebnisses Datensätze ergänzt und vervollständigt werden, dann bietet sich hierfür das SQL-Befehl 'select' an. Weitere informationen ...
1. Intelligente Suche nach Dubletten und doppelten Adressen mit den DataQualityTools in MariaDB
Die DataQualityTools finden Dubletten auch dann noch wenn diese in einem gewissen Rahmen voneinander abweichen. Das ist insbesondere bei Adresslisten hilfreich, wo Schreibfehler und Abweichungen in der Schreibweise eher die Regel denn die Ausnahme sind. Gehen Sie dazu folgendermaßen vor:
- Wenn Sie das nicht schon getan haben, dann laden Sie sich die DataQualityTools hier kostenlos herunter. Installieren Sie das Programm und fordern Sie eine Testfreischaltung an. Damit können Sie dann eine Woche lang ohne jede Einschränkung mit dem Programm arbeiten.
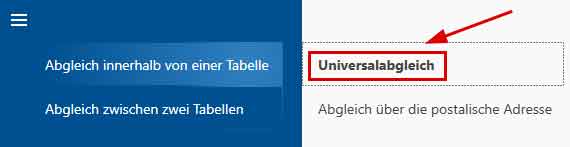
- Die Funktion die wir benötigen findet sich im Menü in dem Block 'Abgleich innerhalb einer Tabelle'. Wählen wir dort den 'Universalabgleich'.
- Nach dem Aufruf dieser Funktion erscheint zunächst die Projektverwaltung. Legen Sie hier ein neues Projekt mit einem beliebigen Projektnamen an und klicken Sie dann auf die Schaltfläche 'Weiter'.
- Dann muss als nächstes die Datenquelle mit den zu verarbeitenden Daten ausgewählt werden. Wählen Sie dazu aus der Auswahlliste bei 'Format / Zugriff auf' MariaDB aus.
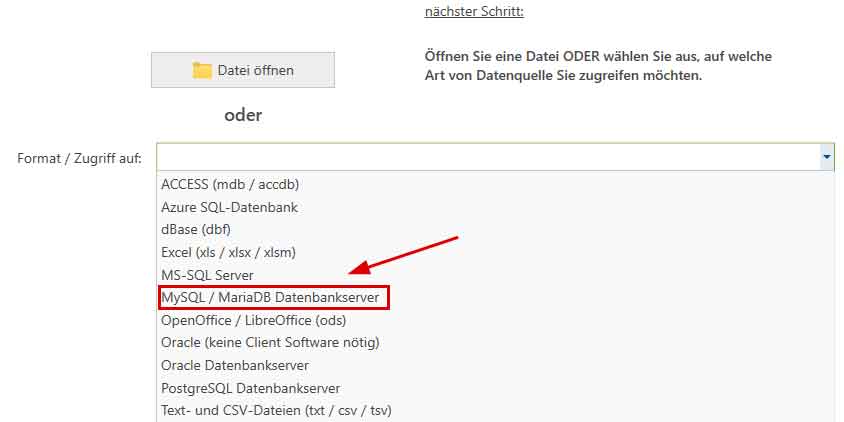
Anschließend ist der Name des Datenbankservers einzugeben. Nach einem Klick auf die Schaltfläche 'mit dem Server verbinden' sind die Zugangsdaten einzugeben. Die Auswahl der gewünschten Datenbank und der Tabelle daraus erfolgt schließlich aus den entsprechenden Auswahllisten. - Anschließend ist dem Programm anzugeben welche der Spalten aus der Tabelle mit verglichen werden sollen:
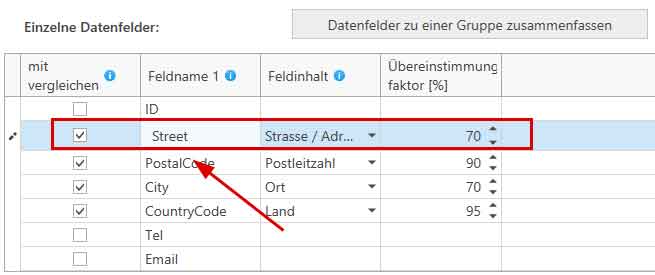
In diesem Beispiel soll unter anderem die Spalte 'Street' mit verglichen werden. Diese enthält den Straßennamen, weshalb aus der Auswahlliste für den Feldinhalt 'Straße / Adresse' ausgewählt worden ist. Und als Schwellwert für den Übereinstimmungsfaktor ist 50% gewählt worden. Der Straßenname muss also zu mindestens 50% übereinstimmen, damit der betreffende Datensatz es als Treffer in das Ergebnis schafft.
Bei Bedarf können einzelne Spalten auch zu einer Gruppe zusammengefasst werden:
Dadurch wird dann der Inhalt der Spalten in der Gruppe vor dem Vergleich zusammengefasst und somit zusammen verglichen. - Mit einem Klick auf die Schaltfläche 'Weiter' kommen wir zu einem Dialog mit weiteren Optionen. Diese benötigen wir hier aber nicht.
- Ein Klick auf die Schaltfläche 'Weiter' startet dann die Suche nach Dubletten. Es dauert nicht lange und es wird eine Zusammenfassung des Ergebnisses angezeigt. Hat das Programm Dubletten gefunden, dann führt ein Klick auf die Schaltfläche 'Ergebnis anzeigen / bearbeiten' zu einer Übersicht über das Ergebnis:
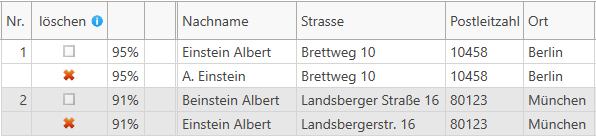
Diejenigen Datensätze die gelöscht werden sollen sind hier mit einem roten Kreuz gekennzeichnet, welches sich bei Bedarf löschen lässt. - Schließlich muss das Ergebnis dann noch weiter verarbeitet werden. Beispielsweise könnten wir die zum Löschen markierten Datensätze direkt in der Ursprungstabelle in MariaDB mit einem Löschkennzeichen markieren. Dazu wählen wir die entsprechende Funktion aus, indem wir zuerst auf 'Markierenfunktionen' klicken:

Und dann auf 'in der Ursprungstabelle markieren':
Anschließend muss dann noch angegeben werden wie die Markierung konkret aussehen soll und in welches Datenfeld diese Markierung geschrieben werden soll: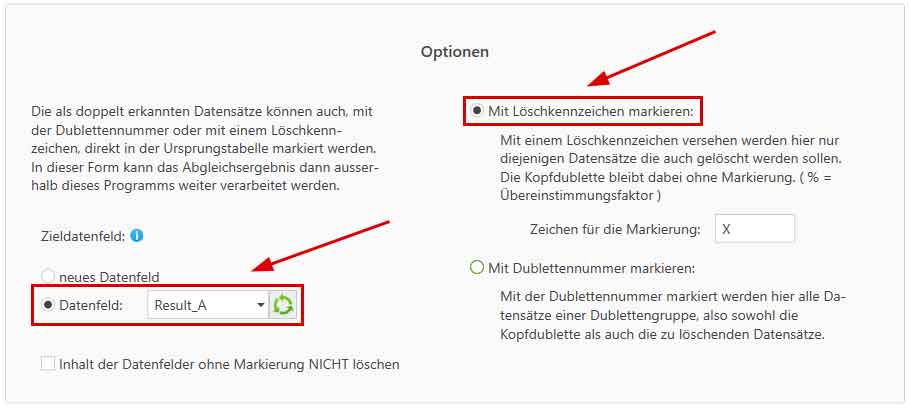
2. Dubletten mit dem 'distinct'-Befehl in MariaDB unterdrücken
Angenommen es sollen aus der Tabelle mit den bestellten Artikeln alle Artikelnummern ermittelt werden die ein einzelner Kunde bestellt hat, wobei im Ergebnis jede Artikelnummer bei einem Kunden nur ein einziges mal vorkommen darf. Die Datenbankabfrage hierfür könnte folgendermaßen aussehen:
SELECT DISTINCT customer_id, article_no
FROM customer_articles
ORDER BY customer_no, article_no
Das 'distinct' bezieht sich dabei auf alle bei 'select' angegebenen Spalten. Im Ergebnis wird hier also jede Artikelnummer mit jeder Kundennummer aufgelistet, aber jede Kombination aus Artikelnummer und Kundennummer nur ein einziges mal. In Kombination mit dem 'into'-Befehl lässt sich damit auch eine Tabelle von doppelten Datensätzen bereinigen:
SELECT DISTINCT customer_id, article_no
INTO table_new
FROM customer_articles
ORDER BY customer_no, article_no
Die von Dubletten bereinigten Daten werden dabei in eine neue Tabelle geschrieben.
3. Dubletten mit dem 'group by'-Befehl in MariaDB ausblenden
Angenommen es sollen aus der Tabelle mit den bestellten Artikeln die Artikelnummern ermittelt werden, wobei im Ergebnis jede Artikelnummer nur ein einziges mal vorkommen darf. Die Datenbankabfrage hierfür könnte folgendermaßen aussehen:
SELECT article_no, COUNT(*), SUM(revenue)
FROM invoice_articles
GROUP BY article_no
ORDER BY COUNT(*), article_no
Diese Abfrage liefert neben der Artikelnummer noch die Anzahl der Datensätze zurück, die diese Artikelnummer enthalten und die Summe der Umsätze aus diesen Datensätzen.
4. Mit dem 'select'-Befehl in MariaDB nach Dubletten suchen
Eindeutige Dubletten, also doppelte Datensätze bei denen alle Treffer bis auf die Groß-Kleinschreibung Zeichen für Zeichen übereinstimmen, sind mit SQL-Abfragen relativ leicht zu finden. Bei der folgenden Abfrage beispielsweise liefert MariaDB alle Datensätze zurück bei denen der Inhalt des Datenfelds 'name' übereinstimmt:
SELECT tab1.id, tab1.name, tab2.id, tab2.name
FROM tablename tab1, tablename tab2
WHERE tab1.name=tab2.name
AND tab1.id<>tab2.id
AND tab1.id=(SELECT MAX(id) FROM tablename tab
WHERE tab.name=tab1.name)
Wie man sieht ist für diese SQL-Abfrage eine Spalte mit einer ID nötig, die den jeweiligen Datensatz eindeutig identifiziert, um sicher zu stellen, dass ein Datensatz nicht mit sich selbst verglichen wird. Darüber hinaus wird diese ID benötigt, um sicher zu stellen, dass der Datensatz mit der größten ID nur in der Spalte 'tab1.id', nicht aber auch in der Spalte 'tab2.id' auftaucht. Auf diese Weise wird sichergestellt, dass der Datensatz mit der größten ID aus einer Dublettengruppe nicht mit gelöscht wird. Die IDs der Datensätze die gelöscht werden sollen stehen in der Spalte 'tab2.id'. In einen DELETE-Befehl für MariaDB eingebaut sieht das Ergebnis dann folgendermaßen aus:
DELETE FROM tablename
WHERE id IN
(SELECT tab2.id
FROM tablename tab1, tablename tab2
WHERE tab1.name=tab2.name
AND tab1.id<>tab2.id
AND tab1.id=(SELECT MAX(id) FROM tablename tab
WHERE tab.name=tab1.name))
Dieser SQL-Befehl lässt sich natürlich leicht dahingehend erweitern, dass neben dem Inhalt des Datenfelds 'name' auch noch weitere Datenfelder, beispielsweise die Datenfelder die zusammen die postalische Adresse enthalten, mit verglichen werden.
Welche Möglichkeiten SQL für die Suche nach unscharfen Dubletten bietet können Sie in dem Artikel 'Unscharfe Dublettensuche mit SQL' nachlesen. Zufriedenstellend gelöst werden aber kann dieses Problem nur von spezialisierten Tools, die eine fehlertolerante Suche nach doppelten Datensätzen bieten, wie zum Beispiel die DataQualityTools.